Intro
It has been more than a year since my last article on this blog. So, I wanted to come back with something unique: going a bit away from a technical developer topic to a more mathematical topic. But don’t get scared by the mathematical notations throughout the page, as I made it as developer-friendly as possible.
In this article, I provide one of the proofs on the lower bound of comparison based algorithms to be , i.e the best time performance that can be achieved using any of the algorithms that use comparison operators. Moreover, I outline some of the well known comparison based sorting algorithms and conduct their analysis.
Since the dawn of computing and computers, the problem of inventing the most optimal sorting algorithms has been a topic of central discussion among computer scientists and mathematicians. Hundreds of sorting algorithms have been proposed by the scientists up to now. The largest part of these research comprises comparison based sorting algorithms.
Definition 1. Comparison based sorting algorithms being one of the types of sorting algorithms, order the elements of an array or list by using a single predicate, either or for any pair of two elements. The following two conditions must be satisfied:
- if and , then
- : or
Now let’s go over some of the most popular comparison based sorting algorithms before proceeding to a general proof for the lower bound.
Example algorithms from the class
Quick Sort
This is a very famous algorithm that works in divide-and-conquer approach, as it was proposed in this research article. It requests no extra space on memory and the number of comparisons used in average is , where and are lower and upper indices of the array to be sorted, respectively. In order to operate, it recursively calls a helper method called partition(A, M, N) to find the pivot index (it is an index used for dividing the array into two parts). Subsequently, it recursively calls the quicksort(A, M, I) and quicksort(A, I, N). In the best case (i.e the lower bound), the partition index always comes out to be in the center of the array , the algorithm would recur twice for and the partition() function would take work. Hence, the recurrence relation for the time complexity would be:
By the Master Theorem, it can be proven that the equation , i.e the Quick Sort algorithm’s time complexity is at least .
Heapsort
Heapsort is another comparison based sorting algorithm that makes use of the heap data structure. Summarizing these steps, first of all, the algorithm builds a max heap from the given array using an algorithm titled heapify(), whose time complexity is . A max heap is a complete binary tree in which the value in each internal node is greater than or equal to the values in the children of that node.
An example of a max heap is described in the following Figure:
 Figure 1. Max heap
Figure 1. Max heap
Hence, the maximum element of the input array , is stored at the root of a max heap. For the next step, the algorithm swaps the root element, i.e the with the last element, which is the (so, we take out the root element, and the size of the heap is decremented). It recursively call the heapify() again on the root until there is no element left. If we let the size of the input as , then the heapify is called times. Finally, we can conclude that, the total time complexity is at least .
Timsort
Timsort is one of the recently invented hybrid algorithms which is also a comparison based, was developed by Tim Peters. It is generally preferred to use for sorting real-world data for modern software data operations. The algorithm is thoroughly described in this article. An array is divided into blocks called the runs. Run of an array is a non-increasing or non-decreasing sub-array of .
Normally, the runs of an array are small-sized, and we perform insertion sort to each of them sequentially, since it is well suited for small lists. Finally, it uses the same merge procedure as used in the Merge Sort Algorithm. The theorem in the article proves that the total time complexity of Timsort is also .
Prerequisites for the proof
In the previous section, we have given a formal definition for comparison based sorting algorithms. Afterwards, we analyzed implementations of three algorithms of the same class, namely Quick sort, Heapsort and Timsort. We have deduced that each of the above mentioned algorithms require at least amount of work.
This section will be devoted for a formal and general mathematical proof, that any sorting algorithm that uses comparison needs at least comparisons.
Since we are concerned about proving the lower bound using decision trees, it is wise to present a formal mathematical definition of a tree beforehand:
Definition 2. A tree is an undirected graph, where any two vertices are connected with a single path.
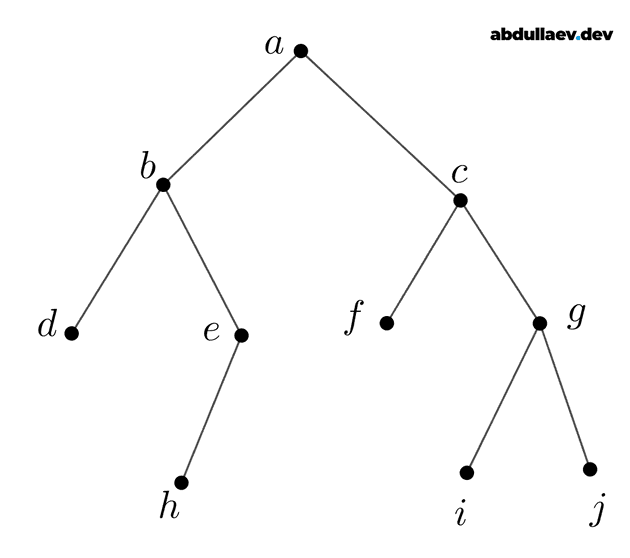 Figure 2. A tree ( — the root of the tree; and — children of ; , , and are internal nodes; , , , and are leaves of the tree)
Figure 2. A tree ( — the root of the tree; and — children of ; , , and are internal nodes; , , , and are leaves of the tree)
The next terminology we will make use of during the proof is so-called an m-way tree:
Definition 3. An m-way tree is a tree, where each internal node has at most children.
 Figure 3. m-way tree. 2-way, 3-way, and 4-way trees.
Figure 3. m-way tree. 2-way, 3-way, and 4-way trees.
By the combinatorics theory, we know that for distinct elements, we will have permutations. The desired sorted order is 1 of those arrangements. We can visualize these permutations using a decision tree (see Figure 4). Hence, from the figure, it is clear that for , we are getting permutations (which is also equivalent to the number of leaves in the tree). The most comparisons occur where the tree has the longest path, i.e the height of the tree, . We note that, the efficiency of a comparison sort depends on the number of such comparisons.
 Figure 4. A decision tree showing order permutations for 3 distinct elements , and .
Figure 4. A decision tree showing order permutations for 3 distinct elements , and .
Theorem 1. An m-way tree with height , has at most leaves.
Proof. We use the mathematical induction. Initially, let . This tree will have only a root and no more than children, where all of them are leaves. Therefore, for , a tree will have at most leaves.
Now, we assume that the theorem is true for all m-way trees of height less than . Let be a m-way tree with height . Leaves of the tree are the union of the leaves of subtrees of .
The height of each of these subtrees is at most . Hence, due to the assumption above, subtrees of , possess at most leaves. Since we have at most such subtrees, and each of them having leaves, the given tree has at most leaves.
As Theorem 1 gives that the number of leaves is at most , i.e, . Taking logarithm of base from both sides yields . Since , we get , where is — the ceiling function.
Result 1. The minimum value of the height of a tree is , and this is equivalent to the minimum number of comparisons.
Result 2. An algorithm based on binary comparisons requires at least comparisons to be performed.
Final proof
Finally, using the results obtained above, we prove that the maximum efficiency of any comparison based sorting algorithm is . Let us recall the definition of Big Omega (see here for differences between Big Omega, Big O and Big Theta):
Definition 3. Let or . If there exist constant positive numbers and () such that the following inequality holds:
then, it is said that is the lower bound of .
We need the following Lemma:
Lemma 1.: , the inequality holds.
Proof: Assuming the inequality to be true, we will try to yield a simple equivalent inequality. By the properties of logarithm, and since the logarithm is an increasing function, we get . Which concludes the proof of this lemma.
Theorem 2. (The main theorem of this article) The number of comparisons which is equivalent to for any comparison based sorting algorithm, belongs to a class of functions in ( is the number of elements in the input list).
Proof. Let us assume and . Since :
We replace terms in the last inequality by only terms, hence, the sum becomes smaller:
Now, by the Lemma 1 and the last inequality:
Finally, for , we have proven .
Hence by Definition 3, belongs to a class of functions (where and ).
Wrapping up. Why should you care?
As software engineers, we use comparison based sorting algorithms directly or indirectly (via third party libraries) in almost any application that we develop. Even though every mathematical detail in this article may not be relevant to understand, the article provides a strict mathematical theory that whatever algorithm we use (whether it is an existing one or we come up with something new) — the fastest time complexity we can achieve is , where is the length of an arbitrary list.